H.265/HEVC is the video compression/decompression standard standardized by ISO/IEC and that is said to have double compression performance of H.264/AVC.
This is expected to be used for high-definition video distribution such as 4K (3840 x 2160) or 8K (7680 x 4320) and video distribution services for mobile devices on the limited bandwidth.
On the other hand, the bottleneck is that it requires more processing resources compared to H.264/AVC.
TMS has developed and commercialized a compact and light software-based decoder by keeping the high image quality of H.265/HEVC.
| Stream Format | Byte stream format (Annex B) |
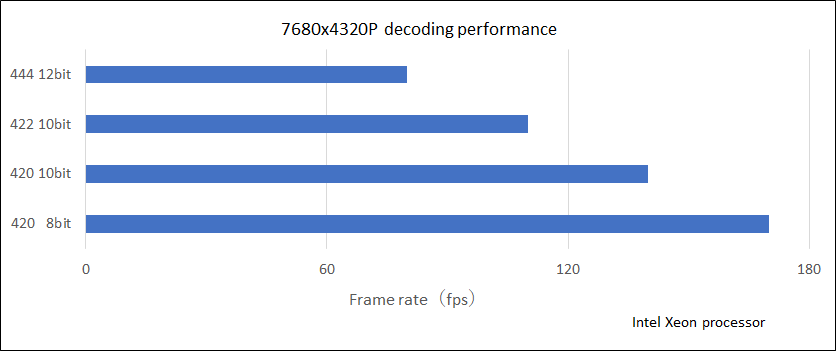
| Image Format | YCbCr 4:2:0/4:2:2/4:4:4/4:0:0 Planar Format |
| Bit Depth | 8 bits/10 bits/12 bits |
| Resolution | 64 x 64 to 7680 x 4320 |
This IP supports both color spaces of YCbCr and YUV.
What is NUMA architecture?
NUMA is an architecture for shared-memory multiprocessor computer systems, in which the cost of accessing the main memory shared by multiple processors is not uniform, depending on the memory area and processor. There are multiple processor-memory pairs (called Node), and from the perspective of a given processor, memory on the same node is called Local Memory, while memory on other nodes is called Remote Memory. Local Memory access latency < Remote Memory access latency If the processor does not need to refer to the memory frequently, it is called Local Memory. By placing data that processors need to refer to frequently in the memory with low access cost, and placing the data that is not frequently referred to in the memory with high access cost, bus congestion is prevented and bus clocking is improved by reducing the number of processors sharing the bus.